Killing Floor 3 Yol Haritası Açıklandı: 2025 ve 2026 İçeriği Belli Oldu




Artık her teknolojik cihaz kullanıcısı, kıyısından köşesinden de olsa bir şekilde yapay zeka ile muhatap olmaya başladı. İster kullanıcı, ister bir geliştirici olun, yapay zeka çağını asla kaçırmamanız gerekiyor.
Yapay zeka çağıyla birlikte karşımıza her geçen gün yeni bir teknik terim çıkıyor. “Token” diye bir söylem mutlaka duymuşsunuzdur veya bugün yarın duyacaksınız. OpenAI ChatGPT, Google Gemini, Meta Llama, xAI Grok veya Anthropic Claude, tüm büyük dil modelleri (LLM’ler) hakkında konuşulurken sürekli “token” kelimesi geçer. Peki token tam olarak nedir ve yapay zeka açısından neden önemli?
Token kelime anlamı olarak jeton, işaret, belirteç ve gösterge gibi anlamlar taşıyor. Yapay zeka dünyasında token’ları AI sistemlerinin iletişim kurmak için kullandığı “kelimeleri” ve ‘cümleleri’ oluşturan “harfler” olarak düşünebilirsiniz. Yani söz konusu yapay zeka olduğunda biz token’ı belirteç şeklinde tanımlayabiliriz.

Token’lar, makine öğrenimi modeline beslenen ve bu model tarafından üretilen metin bölümleridir. Metin bölümleri tek tek karakterler, tam kelimeler, cümleler, kelimelerin parçaları veya daha büyük metin parçaları olabilir.
Genel bir kural olarak, bir token genellikle yaygın İngilizce metinlerde ~4 karakterlik metne karşılık gelir. Bu da yaklaşık olarak bir kelimenin ¾’üne denk düşüyor: 100 token ~= 75 kelime. Aşağıdan Open’AI’ın Tokenizer adını verdini hesaplama aracıyla sağlanan örneğe göz atabilirsiniz:
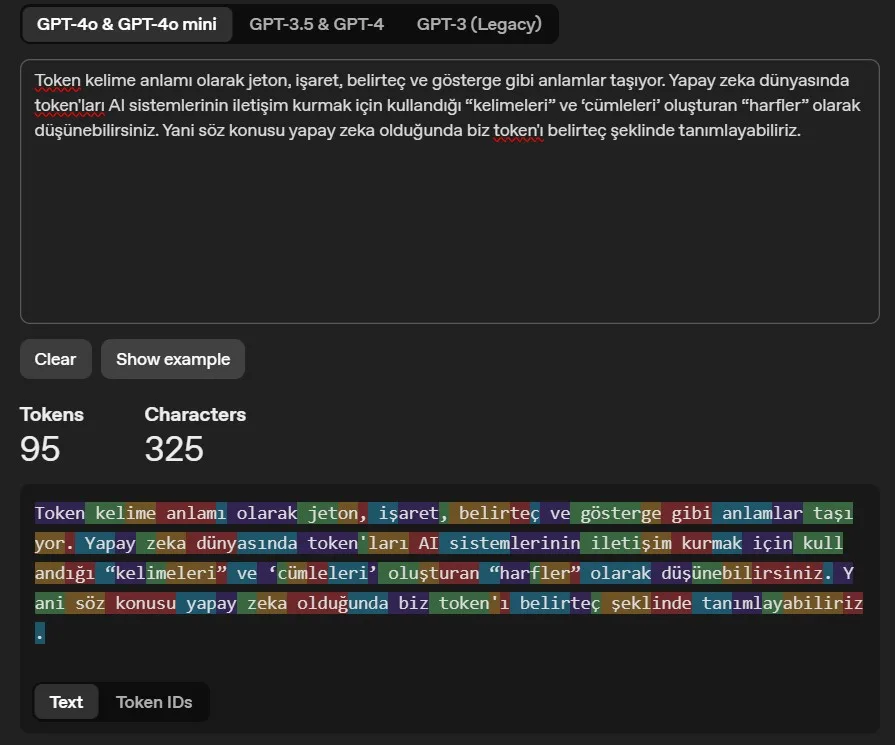
Başka bir deyişle, AI alanında belirteçler algoritmalar tarafından işlenen temel veri birimidir diyebiliriz. Örneğin, metin işlenirken bir cümle belirteçlere bölünür ve AI’da her kelime veya noktalama işareti ayrı bir token olarak kabul edilir. Bu tokenleştirme süreci, AI modellerin daha ileri işleme için verilerin hazırlanmasında çok önemli bir adımdır.
Öte yandan AI tokenleri sadece metinle sınırlı değildir. Token’ler çeşitli veri biçimlerini temsil edebilirler ve yapay zeka algoritmasının bunları anlama ve onlardan öğrenme yeteneğinde çok önemli rol oynarlar. Misal olarak, bilgisayarlı görü alanında bir token, bir piksel grubu veya tek bir piksel gibi görüntü segmentini ifade edebilir. Benzer şekilde, ses işleme söz konusu olduğunda bir ses parçacığı olabilir.
Dediğimiz gibi, belirteç veya gösterge olarak çevirebiliriz bu kelimeyi. Sonuç olarak yazı, ses veya görsel fark etmez, daha sonra kullanmak üzere belirli bir veriyi temsil ediyor. Göstergelerin bu esnekliği, yapay zekanın farklı veri biçimlerini yorumlama ve bunlardan öğrenme yeteneği açısından kritik önem arz ediyor. Ayrıca token’ların sınırlarını anlamak, AI uygulamalarının maliyet etkinliğini ve işlevsel verimliliğini optimize etmek için de çok önemli.
Belirteçler, yapay zeka sistemlerinde, özellikle özellikle dil görevlerini içeren makine öğrenimi modellerinde önemli rol oynuyor söylediğimiz gibi. Bu tür modellerde, AI token’ları algoritmaların kalıpları analiz etmesi ve öğrenmesi için girdi görevi görür. Örnek olarak sohbet robotunu düşünürsek, kullanıcının girdisindeki her kelime bir AI token’ı olarak ele alınır. Bu da yapay zekanın soruyu anlamasına ve uygun şekilde yanıt vermesine yardımcı olur. İşlem süresini ve maliyetini tahmin etmek için metindeki token’ları saymak da önemlidir, çünkü farklı tokenleştirme yöntemleri sayıyı etkileyebilir.

Transformatörler gibi gelişmiş AI modellerinde token’lar daha da mühim. Modeller token’ları toplu olarak işleyerek AI’ın dildeki bağlamı ve nüansları anlamasını sağlar. Bu anlayış, çeviri, duygu analizi ve içerik üretimi gibi görevler için çok çok önemlidir.
Token dediğimiz göstergeler, üretken yapay zeka modellerinin girdiyi yorumlama şekli, çıktıyı tahmin etme şekli ve sabit bir bağlam penceresi içinde bağlamı koruması açısından temel yapı taşı. Standart bir süreçte aşağıdaki aşamalar bulunuyor:
Oldukça yaygın olarak kullanılan metni token’lara ayırma işlemine tokenleştirme (tokenization) deniyor. Tokenleştirme süreci, yapay zekanın insan dilini analiz etmesine ve anlayabileceği bir forma “dönüştürmesine” olanak tanımakta. Belirteçler, AI sistemlerini eğitmek, geliştirmek ve çalıştırmak için kullanılan veriler haline dönüşüyor.

Bu esnada, tokenleştirme dile göre değişiklik gösterebilir. Örnek olarak, İspanyolca “Nasılsın? (How are you)” anlamına gelen “Cómo estás” 10 karakter için 5 token içeriyor. İngilizce olmayan metinler genellikle daha yüksek token-karakter oranı anlamına geliyor, bu da maliyetleri ve sınırları etkileyebiliyor.
API kullanımı, modele ve tokenlerin giriş, çıkış veya önbellek olup olmamasına göre token başına fiyatlandırılır. Fikir edinmek amacıyla OpenAI’ın fiyatlandırma sayfasına bakabilirsiniz. Bazı akıl yürütme modelleri dahili olarak daha fazla token kullanabilir, ancak tamamlanan görev başına gereken token sayısını azaltarak verimliliği artırmayı amaçlar.
Belki de son kullanıcıları en çok ilgilendire kısma geldik. Finali bu bölümle yapalım. Gündelik hayatta kullandığınız her büyük dil modeli, aynı anda işleyebileceği token sayısı bakımından sınırlara sahiptir. Bu sınırlar (context window yani bağlam penceresi), performans, maliyet ve verimlilik üzerinde etkili oldukları için önemli bir etkendir.
Token sınırları bir LLM’nin ne kadar bağlamı işleyebileceğini belirler; bağlam, komutlar, talimatlar ve geçmiş iletişimleri içerir. Daha yüksek token sınırları, modelin daha uzun girdileri yönetebileceği ve uzun konuşmalar boyunca bağlamı koruyabileceği anlamına geliyor.
Nitekim yüksek sınırlar sunan modeller, özellikle uzun metinler veya çok turlu diyaloglar içeren görevler için daha alakalı ve daha doğru yanıtlar sağlayabilir. Böyle modeller daha ayrıntılı sonuçlar verebilir.
Kesinlikle böyle demiyoruz, ancak en azından kapasitesi var. Bağlam penceresinin boyutunu artırmak her zaman daha iyi performans anlamına gelmez. Örneğin LLaMA2-70B gibi geri alma ile güçlendirilmiş modeller, daha büyük token sınırına sahip GPT-3.5-turbo-16k’ya kıyasla özetleme ve sorulara yanıt verme konusunda daha iyidir. İşte popüler modellerle ilgili bir tablo:
| Model | Bağlam Penceresi (Yaklaşık) | Kullanım |
|---|---|---|
| Llama 3 | ~8,000 token | Makale özetleri veya kısa sohbetler gibi orta düzeyde girdi gerektiren görevler için uygundur. |
| GPT-3.5-turbo | ~16,000 token | Uzun diyaloglar, belge analizi ve genişletilmiş içerik için uygundur. |
| GPT-4 | ~128,000 token | Hukuki incelemeler, uzun kod üretimi ve derin araştırma gibi karmaşık görevler için idealdir. |
| Claude-3 | ~200,000 token | Çok uzun içerikleri kolayca işler, kitaplar, kılavuzlar ve ayrıntılı tartışmalar için idealdir. |